Organizing MLflow Runs using Nested Runs
With MLFlow you can track multiple models as separate rows each time you use mlflow.start_run:
import mlflow
with mlflow.start_run(run_name="classifier"):
mlflow.log_metric('Accuracy', 98)
with mlflow.start_run(run_name="regressor"):
mlflow.log_metric('RMSE', 20)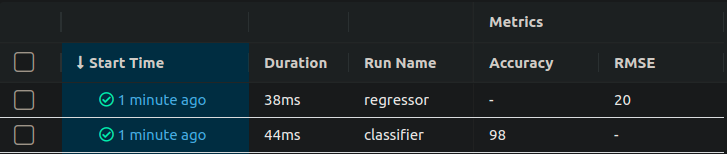
But if you have multiple models per run, it would create multiple rows, which becomes harder to track overtime as the number of model increases.
One option is to utilize the nested option such as with mlflow.start_run(run_name="regressor", nested=True) to create a collapsable view in mlflow.
However this method won’t work if a model is going to be trained at a later time, or when you distributed workoads, since the nested portion of mlflow is not in the same file.
The second method I recommend is through this post: https://stackoverflow.com/questions/56597812/nested-runs-using-mlflowclient
Essentially:
from mlflow.tracking import MlflowClient
from mlflow.exceptions import MlflowException
from mlflow.utils.mlflow_tags import MLFLOW_RUN_NAME, MLFLOW_PARENT_RUN_ID
mlflow_client = MlflowClient(tracking_uri="http://localhost:8585/")
try:
mlflow_experiment = mlflow_client.create_experiment("test")
except MlflowException:
mlflow_experiment = mlflow_client.get_experiment_by_name("test").experiment_id
mlflow_parent_run = mlflow_client.create_run(
experiment_id=mlflow_experiment,
tags={MLFLOW_RUN_NAME: "Models"},
)
mlflow_children_run = mlflow_client.create_run(
experiment_id=mlflow_parent_run.info.experiment_id,
tags={
MLFLOW_PARENT_RUN_ID: mlflow_parent_run.info.run_id,
MLFLOW_RUN_NAME: "model 1",
},
)
mlflow_client.log_metric(mlflow_children_run.info.run_id, f"Accuracy", 98)
mlflow_client.set_terminated(mlflow_children_run.info.run_id, status="FINISHED")
mlflow_children_run = mlflow_client.create_run(
experiment_id=mlflow_parent_run.info.experiment_id,
tags={
MLFLOW_PARENT_RUN_ID: mlflow_parent_run.info.run_id,
MLFLOW_RUN_NAME: "model 2",
},
)
mlflow_client.log_metric(mlflow_children_run.info.run_id, f"RMSE", 20)
mlflow_client.set_terminated(mlflow_children_run.info.run_id, status="FINISHED")
mlflow_client.set_terminated(mlflow_parent_run.info.run_id, status="FINISHED")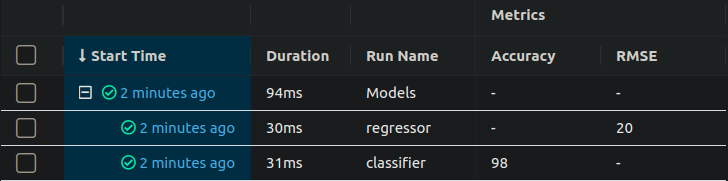
The idea is to keep track of mlflow_parent_run.info.run_id. Whenever you create a mlflow run through create_run, it takes in a MLFLOW_PARENT_RUN_ID, which allows you to collapse the runs through a parent.
The downside is you’ll need to use the MlflowClient directly without the context manager mlflow.start_run, and you’ll need to use set_terminated to manually complete the run, otherwise you won’t get the green checkbox.
The mlflow_parent_run is pickle-able, which means you can carry this through multiple modules or other distributed workloads as long as the target machine can access mlflow.